

Nobody Tells You What's Actually Inside TikTok's Algorithm. Here It Is on AWS.
A breakdown of the feedback loop, ranking model, and real-time inference pipeline behind one of the most effective recommendation systems ever built.

Every time someone opens TikTok, they think they’re browsing videos. They’re not. They’re submitting data points to a ranking system that has been learning their behavior since the first swipe.
The videos are the output. The interesting part is what happens before you see them.

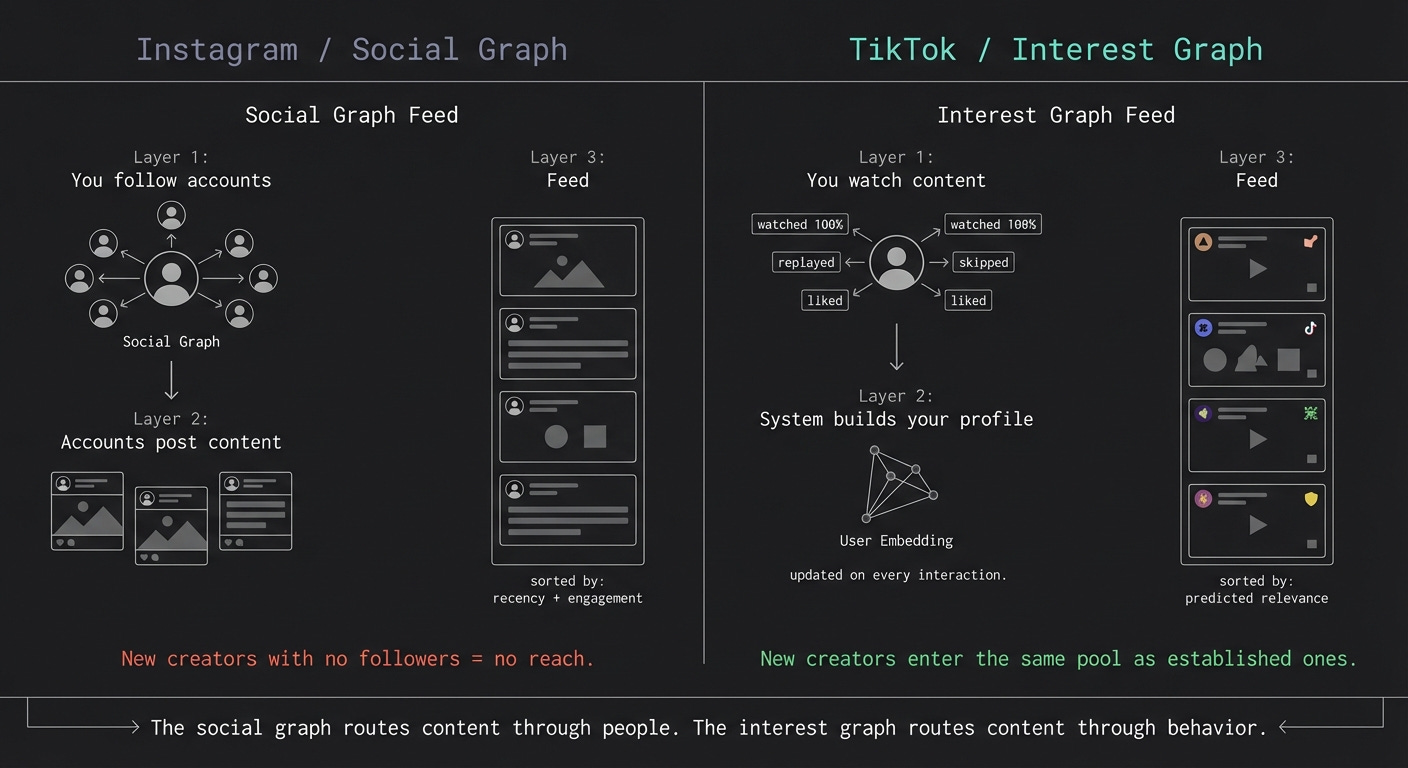
How most people picture it
The mental model most people carry over from Instagram goes like this: you follow accounts, those accounts post content, the app shows you that content in some combination of recency and engagement.
TikTok does not work that way. The social graph is almost irrelevant. You could open TikTok tomorrow having followed no one and get a feed that is more calibrated to you than your Instagram explore tab after three years of use.
TikTok’s feed is not pulled from a social graph. It’s built from a ranking model that scores available content against a continuously updated profile of you
The actual loop
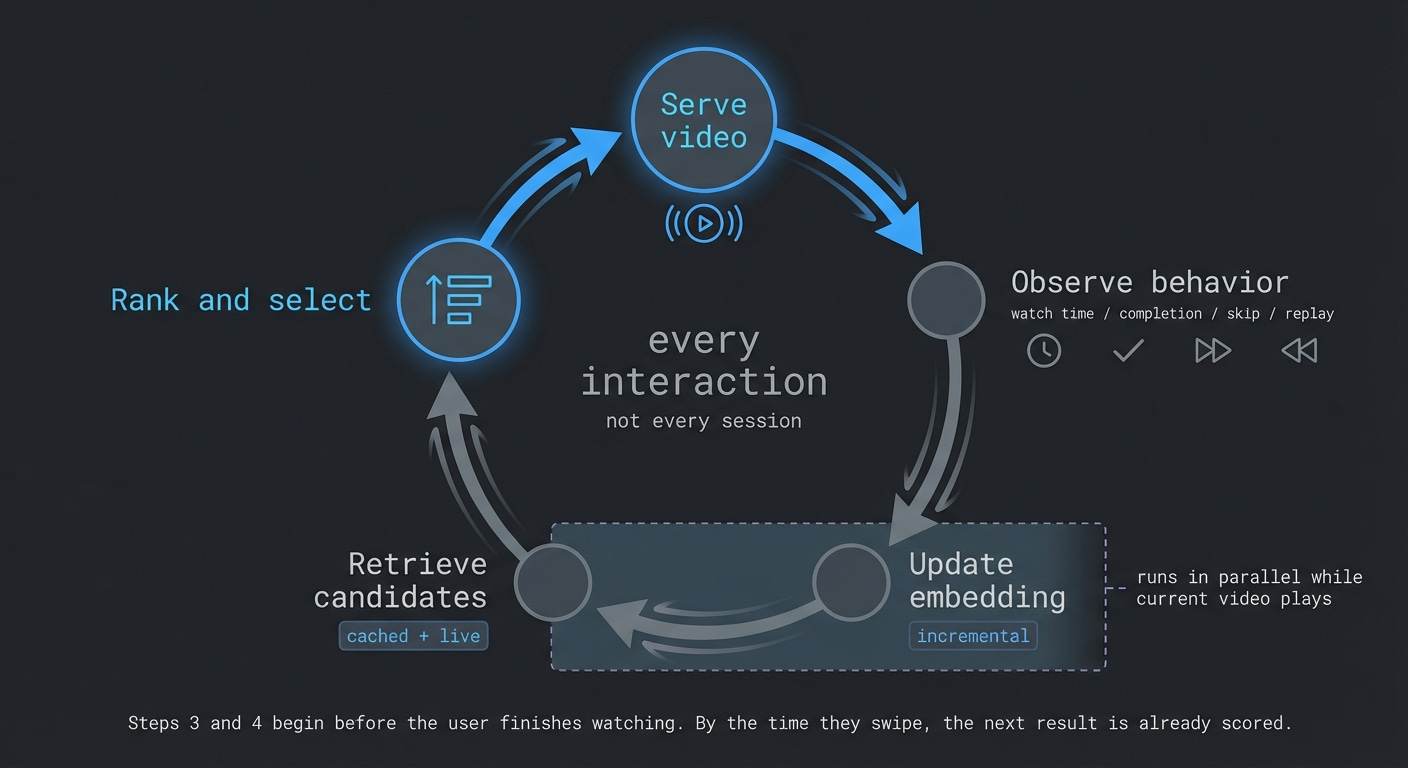
The core of TikTok is a feedback loop:
Show a video
Observe what you do
Update your user profile
Rank the next candidates
Show the best one
Repeat
This doesn’t run once per day or once per session. It runs on every interaction. But it’s worth being precise about what “update” means here. The system isn’t recomputing everything from scratch on each swipe. It’s combining cached embeddings, precomputed candidate sets, and incremental updates to your profile. The loop is continuous, but the computation is layered and largely parallelized.
By the tenth video in a session, the system has a sharper picture of your current mood than most people have of themselves.
What the system actually measures
Most people assume TikTok’s signal is likes and shares. Those matter, but they’re not the foundation.
The strongest signal is watch time, specifically completion rate. A video watched to the end, then replayed, is the clearest message you can send the system. A video skipped in the first two seconds is equally clear in the opposite direction.
Watch time and completion account for a large share of the ranking weight. The rest is distributed across shares, comments, likes, and follows, roughly in that order.
Explicit actions carry less weight than passive behavior because passive behavior is harder to fake. You can like something out of politeness. You can’t fake watching something twice.
What makes this more interesting is that TikTok isn’t running a single-objective optimization for raw attention. The system is balancing multiple signals including watch time, engagement, and longer-term retention behavior. Attention is the dominant proxy, but the objective function is more nuanced than pure watch time maximization.
How new content actually spreads
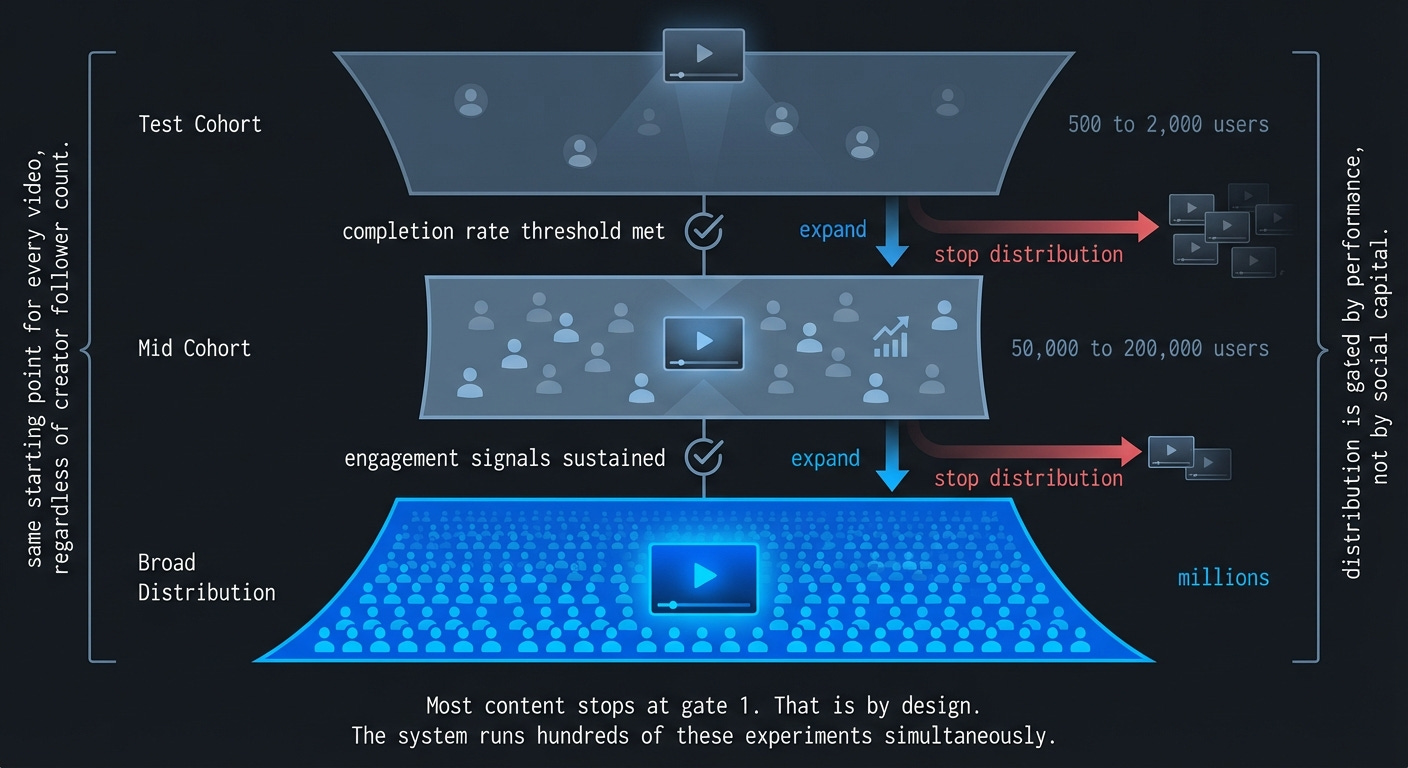
Before getting to the infrastructure, there’s a mechanism worth understanding: progressive amplification.
Every piece of content starts with a small test audience. If the engagement signals from that cohort cross a threshold, the system expands distribution to a larger group. Strong performance there triggers another expansion. Weak performance stops the cycle.
This is why a creator with zero followers can go viral overnight, and why a creator with a million followers can post something that reaches almost nobody. Distribution is not gated by social capital. It’s gated by performance in the test cohort.
What’s happening behind a single swipe
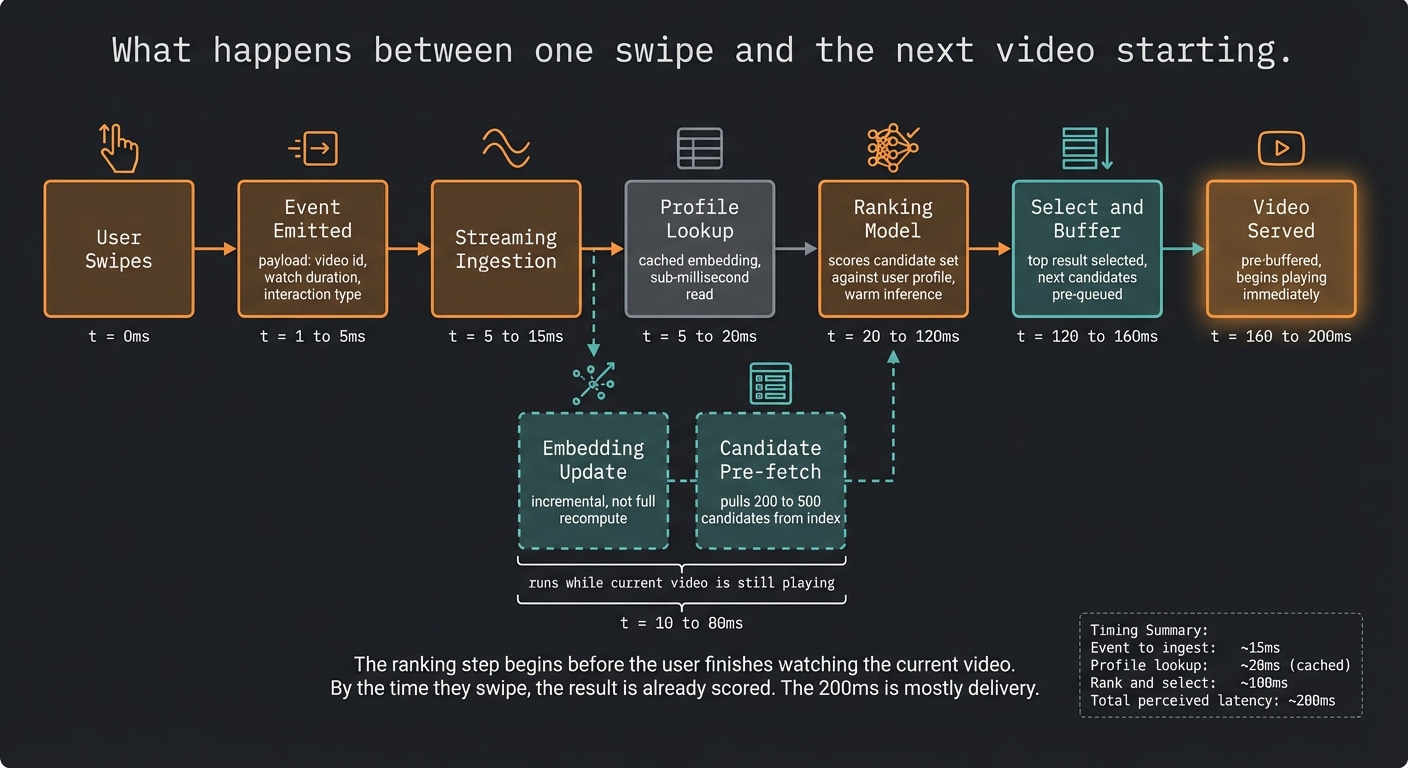
Now strip out the product layer and look at the infrastructure.
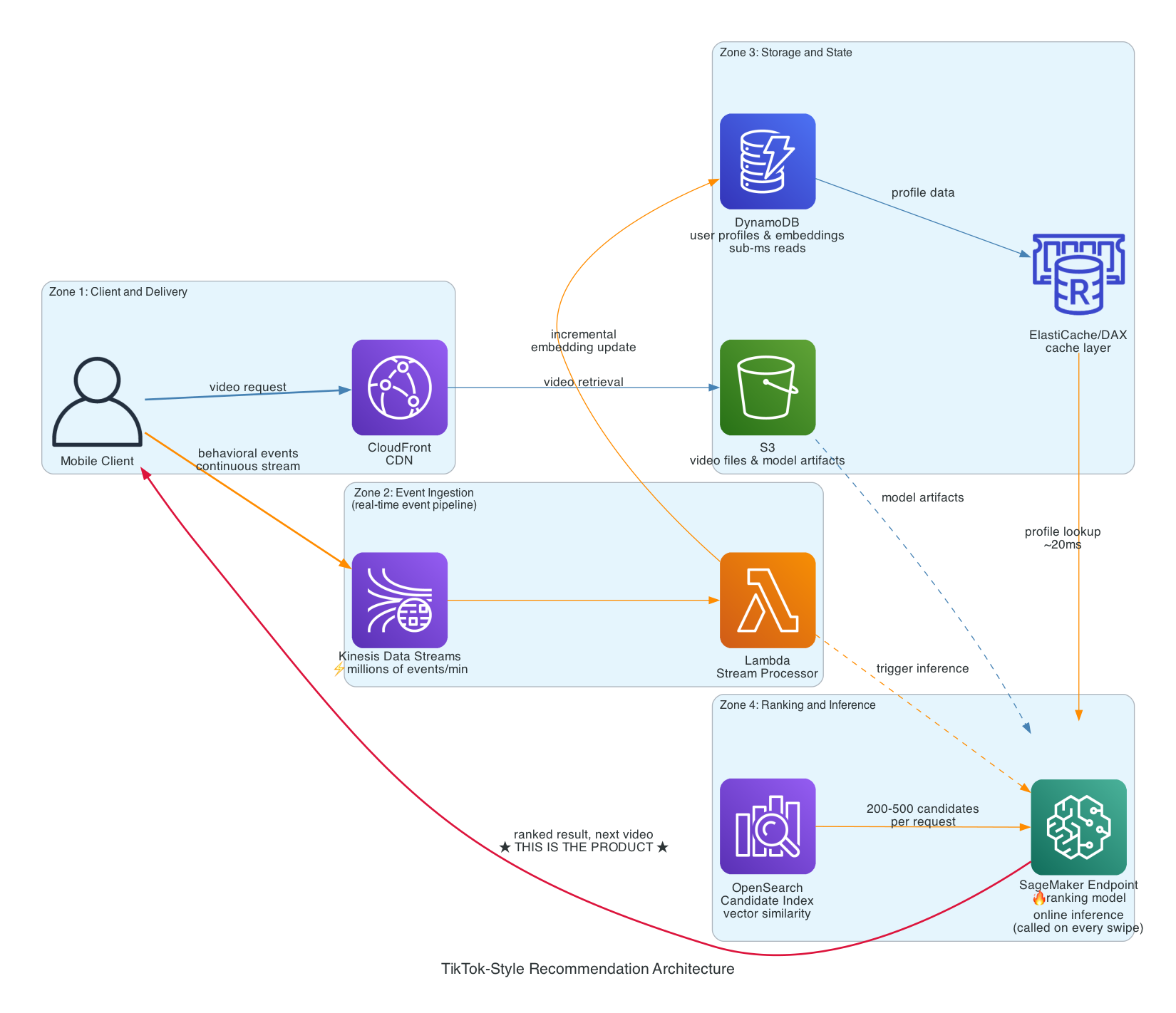
When you swipe to the next video, a chain of events fires. An event is emitted containing what you watched, for how long, and whether you interacted. That event hits a streaming ingestion layer. Downstream, multiple things happen in parallel: your user embedding gets updated incrementally, a candidate retrieval system pulls a few hundred potential videos that match your current profile, and a ranking model scores those candidates. The top result gets served while the next retrieval cycle is already running.
The key word is parallel. The naive mental model is sequential: watch, then update, then rank, then serve. The real system pipelines these steps so that by the time you’re three seconds into a video, the system is already scoring candidates for what comes next.
How you’d build this on AWS
This architecture maps cleanly to AWS primitives.
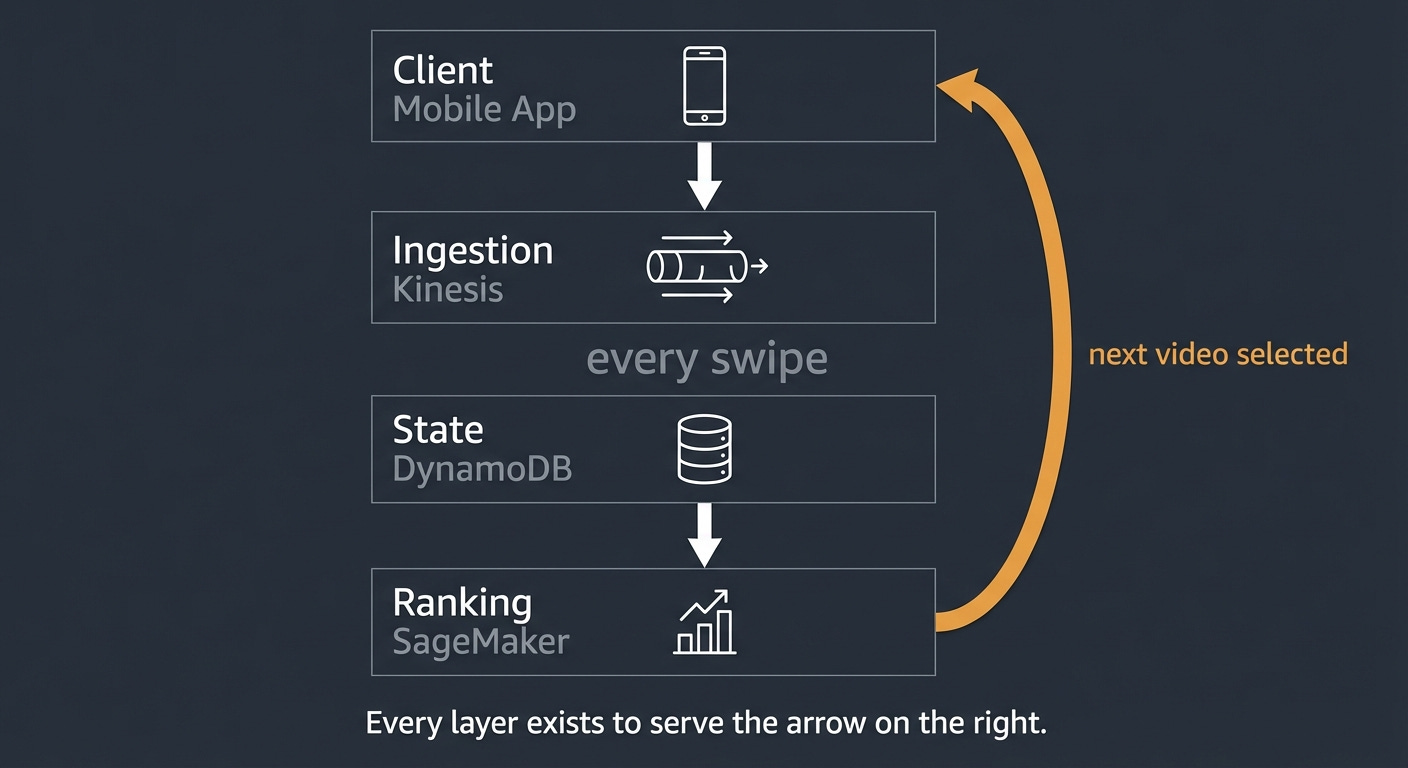
Kinesis handles event ingestion. Every watch event, skip, replay, and interaction flows through Kinesis Data Streams. This is the entry point to the feedback loop. At scale, this pipeline needs to absorb millions of events per minute without creating backpressure on the serving layer.
DynamoDB holds user state and profile vectors. The embedding lookup that happens before ranking needs to be fast, single-digit millisecond reads. DynamoDB with DAX for caching gets you there.
S3 and CloudFront handle video storage and delivery. Content is stored in S3, CloudFront distributes it globally. This is the least architecturally interesting part of the system, but it’s where most of the bandwidth cost lives.
SageMaker runs the ranking models. The important distinction here is that this is online inference, not batch prediction. The model endpoint needs to be warm at all times, low-latency, and versioned so ranking experiments can run in parallel without affecting production.
Lambda or ECS-based microservices orchestrate the pipeline steps. The candidate retrieval and ranking calls need to run with enough parallelism to stay within the latency budget while a user is mid-swipe.
The critical framing: this is a real-time inference system that runs on every interaction, not a batch ML pipeline that recalculates recommendations overnight. The infrastructure cost profile is completely different. You are paying for constant compute, not periodic compute. That distinction drives almost every architectural decision in a system like this.
Why removing the social graph matters
On a follower-based platform, a new creator with no audience gets seen by almost no one. Discovery is gated by existing network size. The rich get richer.
TikTok’s system sidesteps this through the progressive amplification mechanism described above. Every video starts on equal footing in the test cohort. The social graph doesn’t accelerate distribution, and its absence doesn’t block it.
This creates a different content dynamic. New creators can break through quickly. Established creators can’t coast on their follower count. And the system is always running fresh experiments rather than routing traffic through fixed nodes in a social network.
The tradeoff is that optimizing for attention signals doesn’t automatically optimize for content quality. A video that generates strong reactions scores well regardless of whether those reactions are positive or negative. The system is measuring what you actually do, not what you wish you had done.
The real tradeoffs
Any architecture this effective at real-time ranking carries costs that are worth being honest about.
Inference at scale is expensive. You are calling a model endpoint on every interaction, not once per session. The compute bill for continuous ranking is a meaningful fraction of total infrastructure spend, and it scales linearly with engagement, which means your most successful moments are also your most expensive ones.
Content moderation becomes structurally harder. A ranking system optimizing for engagement will surface content that generates strong reactions, and the system has no native way to distinguish between “engaging because it’s delightful” and “engaging because it’s outrageous.” Moderation has to operate as a separate layer on top of the ranking system, which creates a constant lag between what gets amplified and what gets reviewed.
The cold start problem for new users is also real. The first few sessions are mostly exploration, which means the feed is less calibrated early on and some users churn before the system has enough signal. Onboarding flows that collect explicit interest data help, but they’re a patch on top of a fundamentally cold system.
And the entire infrastructure runs continuously. There is no off-peak. Every swipe at every hour needs to complete the full pipeline within the latency budget. That operational requirement shapes everything from service design to on-call rotation.
How you actually hit the latency budget
Saying “keep latency low” is not an architecture decision. Here are the ones that actually move the number.
The biggest lever is pre-computation. You don’t rank on every swipe, you rank during the current video. While the user is three seconds into what they’re watching, the system is already scoring candidates for what comes next. By the time they swipe, the result is ready. The swipe triggers delivery, not ranking.
The second lever is candidate retrieval. The ranking model is fast when you feed it 200 candidates. It becomes the bottleneck when you ask it to score millions of videos. Approximate nearest neighbor search, using a vector index like OpenSearch, narrows the pool from millions to hundreds before the ranker runs. That single architectural decision accounts for more latency savings than any model optimization.
The third lever is keeping the model warm. A cold SageMaker endpoint adds hundreds of milliseconds to every request. Provisioned concurrency on Lambda and persistent endpoints on SageMaker eliminate cold starts. At the scale where this system becomes interesting, cold starts are not a performance nuisance, they are a product failure.
The fourth lever is separating the write path from the read path completely. The embedding update should never block the ranking step. Kinesis decouples them. The event is captured immediately, the update happens asynchronously, and the ranking step reads the last known good state from cache without waiting for the write to complete. DAX in front of DynamoDB means most profile lookups never reach the database at all.
The fifth lever is model size. The model you train offline does not have to be the model you serve. Quantization and distillation can cut inference time significantly with minimal accuracy loss. A smaller, faster model that updates on every swipe will outperform a larger, slower one that updates once per session. This is the same tradeoff that defines the whole system: speed of learning beats sophistication of model.
None of these are exotic techniques. They are standard practice in high-throughput inference systems. The reason most teams don’t achieve this latency profile is not that the tools are unavailable. It’s that each lever requires a deliberate architectural commitment, and those commitments compound. You can’t bolt low latency onto a system designed for batch processing. It has to be the starting constraint, not an afterthought.
Why this architecture wins
TikTok became one of the fastest-growing consumer apps in history not because it had better videos. The content library on YouTube is orders of magnitude larger.
It won because the feedback loop is tighter and the latency budget is treated as a product requirement, not an infrastructure concern. The time from “user watched something” to “that information changes what they see next” is measured in milliseconds. The system learns within a session, not across sessions.
A fast, slightly imprecise ranking engine that updates on every swipe will outperform a more sophisticated one that recalculates daily. The compound effect of thousands of micro-updates per session is what creates the feeling that TikTok already knows what you want.
That feeling has a name: latency.
The AWS primitives to build this exist today. Kinesis, DynamoDB, SageMaker, OpenSearch, CloudFront. The architecture is not secret. What’s hard is the discipline of treating every millisecond as a product decision, keeping the inference cost low enough that the unit economics survive at scale, and maintaining the pipeline under continuous load with no off-peak window to recover.
Most teams can assemble the components. The ones who build something defensible are the ones who close the loop fast enough that users never notice it exists.
The west has valued enlightenment; and in its wake, cherished romantic interiority. The algorithmic feed spits on both.
https://nathankyoung.substack.com/p/notes-on-the-cultural-revolution?r=2kp7ol